I build ML, RecSys, and LLM systems that serve customers at scale, and write about what I learn along the way. Join 7,500+ subscribers!
Evals for Long-Context Question & Answer Systems
|
Hey friends, I've been thinking a lot about evals for long-context Q&A since building aireadingclub.com and wrote an introduction here. It covers (i) key evaluation metrics, (ii) how to generate questions for Q&A evaluation datasets, (iii) how to build LLM-evaluators to assess Q&A performance, and (iv) a review of several existing benchmarks. I hope you find it useful. P.S. If you want to learn more about evals, my friends Shreya and Hamel are hosting their final cohort of “AI Evals for Engineers and PMs” in July. Here’s a 35% discount code. • • • 👉 Read in browser for best experience (web version has extras & images) 👈 While evaluating Q&A systems is straightforward with short paragraphs, complexity increases as documents grow larger. For example, lengthy research papers, novels and movies, as well as multi-document scenarios. Although some of these evaluation challenges also appear in shorter contexts, long-context evaluation amplifies issues such as:
In this write-up, we’ll explore key evaluation metrics, how to build evaluation datasets, and methods to assess Q&A performance through human annotations and LLM-evaluators. We’ll also review several benchmarks across narrative stories, technical and academic texts, and very long-context, multi-document situations. Finally, we’ll wrap up with advice for evaluating long-context Q&A on our specific use cases.
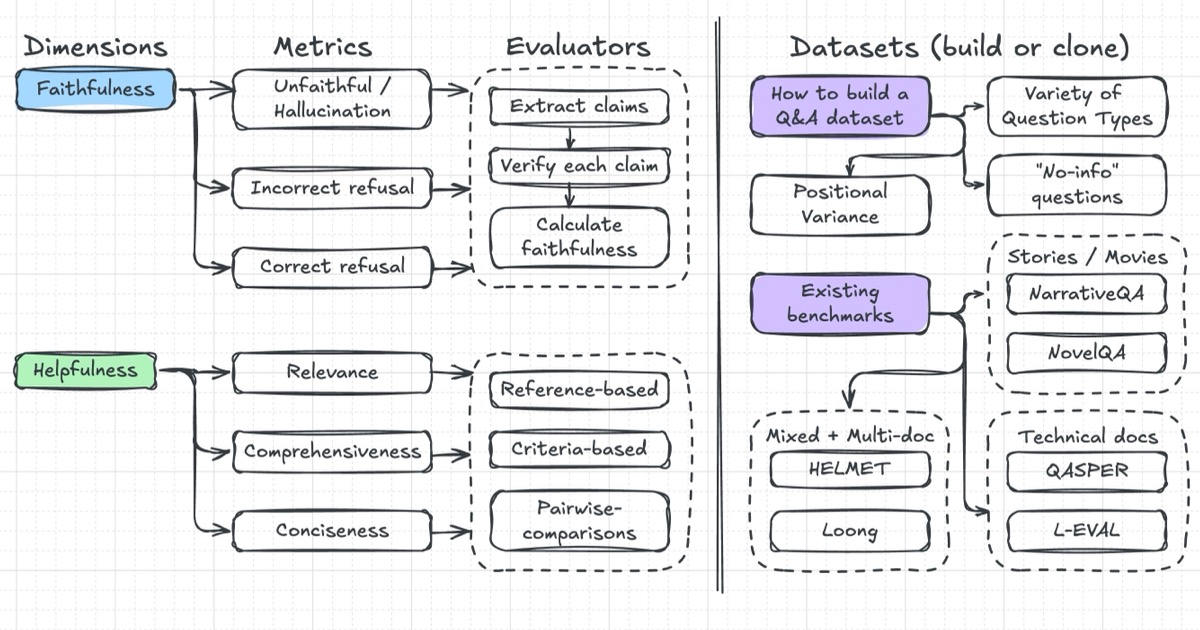
An overview of what we'll cover in this writeup By the way, if you want to learn more about evals, my friends Hamel and Shreya are hosting their final cohort of “AI Evals for Engineers and PMs” in July. Here’s a 35% discount code. Key Evaluation MetricsEvaluating Q&A systems goes beyond just checking for factual accuracy. Specifically, we might want answers to be based solely on the provided text, not the model’s knowledge. But even technically correct answers aren’t necessarily helpful. Thus, to evaluate Q&A systems effectively, we should consider two orthogonal dimensions:
Faithfulness measures whether an answer strictly relies only on the source document. This means the model shouldn’t add external information or make things up (aka hallucinate). Faithfulness is especially important for legal agreements, financial contracts, or medical and insurance forms, where answers must be based solely on the given text. Faithfulness is synonymous with groundedness, where answers must be anchored on the original document. Faithfulness also includes the Q&A system knowing when to say, “I don’t know.” If the source document doesn’t contain the answer, the ideal response is something like, “I don’t have that information in the provided text.” Related to this challenge are two errors by Q&A systems:
We also want to distinguish faithfulness from correctness. An answer might be correct based on general knowledge but still be unfaithful if it contradicts the document. Examples include patient-specific medical instructions that differ from the usual guidelines, definitions in financial or legal agreements that depart from the standard, and historical fiction with alternate timelines. Users depend on Q&A systems to return responses that are faithful to their specific documents, rather than general truths. For systems that provide citations, we can also assess citation accuracy. This evaluates if the cited text supports the answer. Benchmarks like QASPER explicitly evaluate whether models reference the right supporting evidence for the answer. This combined assessment—checking both faithfulness and citation accuracy—provides finer-grained metrics on overall faithfulness and evidence retrieval. However, a faithful answer isn’t always a helpful answer. This is where we also want to evaluate the helpfulness of responses. Helpfulness measures whether an answer is relevant, sufficiently detailed, yet concise. Relevance means the answer directly addresses the user’s question without straying off-topic. Comprehensiveness ensures the answer contains the necessary details. Conciseness balances comprehensiveness by ensuring the answer is succinct, without unnecessary details or fluff. While a brief, one-sentence response to a complex question might be faithful, it falls short of being helpful if the answer needs more details. Conversely, overly long responses filled with extraneous details can overwhelm users, making it hard for users to find the core answer they need. An ideal response should contain most, if not all, of the relevant information from the source document, in a concise way that meets the user’s needs. A study by Xu et al. (2023) found that domain experts in fields like biology or economics preferred answers that were both comprehensive and faithful, particularly for long-form questions. In contrast, crowd-workers often emphasized surface aspects such as conciseness or detail. Thus, if we’re building our Q&A system for power users and experts, the system should focus on returning faithful and comprehensive answers. There’s a tension between faithfulness and helpfulness. An answer can be perfectly faithful yet totally unhelpful. For example, if we ask about a legal contract: “What happens if the tenant misses a payment?” A faithful yet unhelpful answer could be, “Clause 4.2 of the lease agreement addresses missed payments.” Although technically accurate, it’s not helpful as it doesn’t tell us what actually happens if a payment is missed. The same goes for Q&A systems that simply copy-paste large sections from documents. A useful system should synthesize the information and return a direct answer that meaningfully addresses the user’s question. All in all, the best answers achieve both faithfulness and helpfulness by:
Building an Evaluation DatasetEvaluating long-context Q&A begins with creating a robust evaluation dataset. This involves testing how well a Q&A system can navigate book-length documents to answer questions. First, we’ll start with creating a variety of realistic, context-specific questions. While human annotators excel at crafting great questions, this is time-consuming and impractical at scale, especially for lengthy documents. A more efficient approach is to use language models to draft questions that annotators can then accept or edit—this augments human judgment with machine speed and scale. However, just scaling with a language model isn’t enough. We also need to guide the model toward generating natural, useful questions. Thus, instead of vague prompts like “Generate questions about this chapter,” we can be more specific, such as: “Summarize the main characters in this chapter. Then, generate one question about each character’s backstory based on what we’ve read so far.” More precise prompting helps steer models toward producing useful questions for our evaluation dataset. This approach builds on the methodology of existing benchmarks. NarrativeQA intentionally generates questions based on summaries rather than full texts. This encourages questions that test narrative comprehension rather than shallow fact recall. For the same reason, QASPER creates questions based on abstracts from academic papers that models then answer based on the full paper. By learning from these benchmarks, we can construct evaluation datasets that effectively measure meaningful comprehension of long-context documents. We’ll want to ensure question diversity when creating questions. Having a range of question types helps us evaluate the Q&A system’s capabilities without overfitting to any single type of question. Depending on our use case, an evaluation dataset could include a mix of:
Our Q&A evals should also be robust to the position of evidence within the document. We ensure this by having questions with evidence that appear at the beginning, middle, or end, as well as creating multi-hop questions that require details from several sections or documents. Benchmarks like HELMET evaluate how model accuracy changes based on the location of supporting information, evaluating the model’s ability to pay attention to and combine information from the entire document instead of relying solely on nearby context. Methods to Assess Q&A PerformanceHuman annotators are crucial for building a high-quality, ground-truth dataset. This is useful for calibrating automated evaluators, and with enough annotated examples, we can also train evaluation classifiers or reward models. Here’s how this might look for the metrics of faithfulness and helpfulness: Faithfulness annotation involves evaluating whether an answer accurately reflects the source text. Ideally, we’d like simple binary labels—faithful or unfaithful—but reality is rarely that straightforward. Answers typically exist on a spectrum. As a result, a mostly correct answer that misses a critical detail should be graded differently from one that incorrectly represents minor or peripheral information. Related to faithfulness is the “no-info” annotation. This checks whether the model correctly identifies when the provided context doesn’t contain the information to answer the question. The goal here is to identify hallucinations, where the model invents answers instead of acknowledging the gap. As part of this exercise, we could have the following labels:
Helpfulness comparisons involve annotators judging which of two faithful answers better meets the user’s needs. Rather than asking for absolute ratings, annotators make relative judgments, answering a straightforward question: “Which answer is more helpful?” People find comparing two answers easier than assigning absolute ratings, resulting in greater consistency across annotators. When comparing helpfulness, annotators should consider:
Here are some practical tips for setting up a reliable annotation process:
That said, while human annotation is traditionally considered the gold standard, it’s not always practical or scalable, especially for large documents. This is where LLM-evaluators (also called “LLM-as-Judge”) can help. Via this approach, we provide clear criteria—or our annotation guidelines—to a model, and have it evaluate the quality of Q&A responses. But first, it’s important to recognize why older automated metrics fall short. Historically, the language modeling community relied on n-gram-based metrics like BLEU and ROUGE, which measure word overlap between generated responses and reference answers. Although these metrics work somewhat for tasks like machine translation, they correlate poorly with human judgment on open-ended tasks such as Q&A. For example, the L-Eval benchmark highlighted the poor correlation between token-overlap metrics and human judgment for Q&A responses. A correct answer using words that differ from the reference answer can get unfairly penalized by a low ROUGE score, leading to a misleading negative signal. This is especially noticeable when model responses and reference answers vary in length. Without length normalization, token-overlap metrics can mistakenly reward verbose yet mediocre answers over concise, accurate ones. This is why model-based evaluation is increasingly popular—it offers more reliable and nuanced evals than traditional metrics. We typically start by calibrating an LLM-evaluator against a high-quality, human-annotated dataset. With ground truth, we can evaluate our LLM-evaluator by measuring its recall and precision on faithfulness annotations, and its correlation with human judgments on the helpfulness comparisons. To evaluate faithfulness, we can treat answers as collections of individual claims, each of which can be verified as true or false. This is similar to approaches used in NLI-based and Q&A-based summarization metrics, and claim generation and verification. Breaking answers down into atomic claims helps us pinpoint where hallucinations occur. Here’s how it works:
This fine-grained approach, as demonstrated by evaluations like SummaC, QAFactEval, and RefChecker, offers more interpretability and nuance. Rather than labeling an entire answer as faithful or not, we gain a nuanced understanding of which claims are incorrect. This also allows assigning partial credit to mostly faithful answers with minor inaccuracies. We can also go a step further by requiring the model to provide citations for each claim. This helps distinguish between two different failure modes: hallucinations (making up answers) and retrieval failures (not retrieving relevant information). To evaluate our evaluator, we can compare its judgments to human annotations on two key metrics: (i) recall (of all unfaithful claims, how many does the evaluator correctly flag?) and (ii) precision (of all claims the evaluator flags as unfaithful, how many are truly unfaithful?) Evaluating helpfulness requires a more nuanced approach because often, there isn’t a definitively “helpful” way to answer. Different situations might call for varying levels of detail or explanation styles. Here are several strategies we can consider:
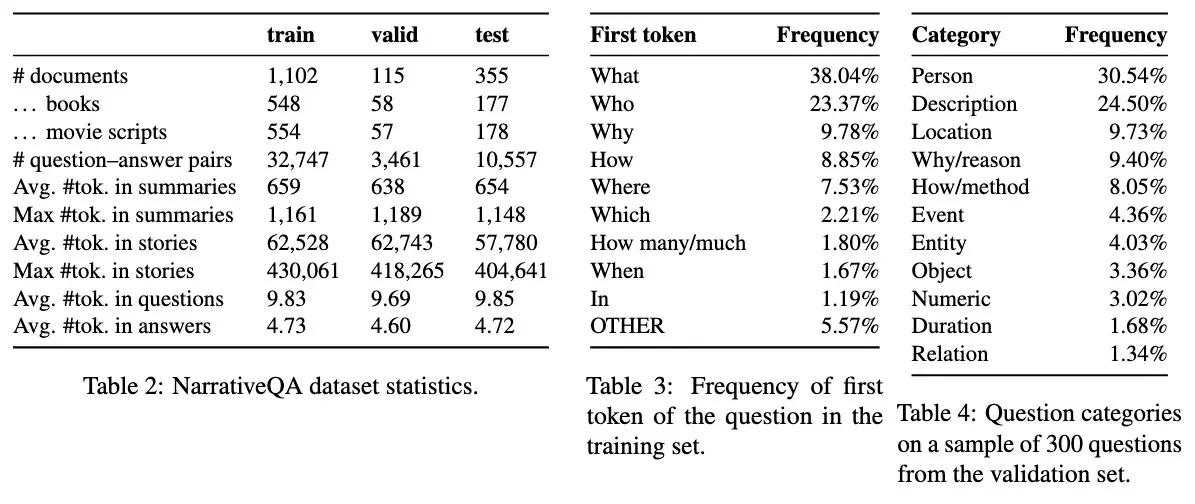
To calibrate an LLM-evaluator on helpfulness, pairwise comparisons are especially reliable. By presenting pairs of answers to annotators and LLM-evaluators, we can measure their alignment—how often they agree on the more helpful answer. Correlation metrics, such as Cohen’s Kappa, quantify this alignment effectively. For example, L-Eval found that GPT-4’s pairwise comparisons correlated strongly with human preferences once properly calibrated. What We Can Learn from Existing BenchmarksTo ground our discussion so far, let’s look at some benchmarks for long-context Q&A. Besides providing a common standard, these benchmarks highlight challenges we might encounter in dataset creation and evaluation. Since these datasets are likely already part of model training data, we shouldn’t rely solely on them to evaluate our Q&A system. Instead, we’ll want to create evaluation datasets tailored to our use case. We’ll cover six benchmarks spanning (i) narrative documents, (ii) technical and academic documents, and (iii) very long or multi-document contexts. The NarrativeQA dataset, introduced by Kočiský et al. in 2017, is designed to test genuine narrative comprehension rather than surface-level pattern matching. Unlike earlier datasets that allowed models to answer by extracting single sentences, NarrativeQA requires synthesizing information scattered across novels and movie scripts to generate answers. First, the authors collected over 1,500 stories from Project Gutenberg and movie script websites, along with their corresponding plot summaries from Wikipedia. Annotators then generated question-answer pairs based only on these summaries, without viewing the full texts. (Conversely, models answered questions based on the full text but not the summaries.) This deliberate approach ensured that answers couldn’t be found by simple text matching, focusing the evaluation on understanding the entire text. The resulting dataset contains 46,765 question-answer pairs focused on narrative comprehension.
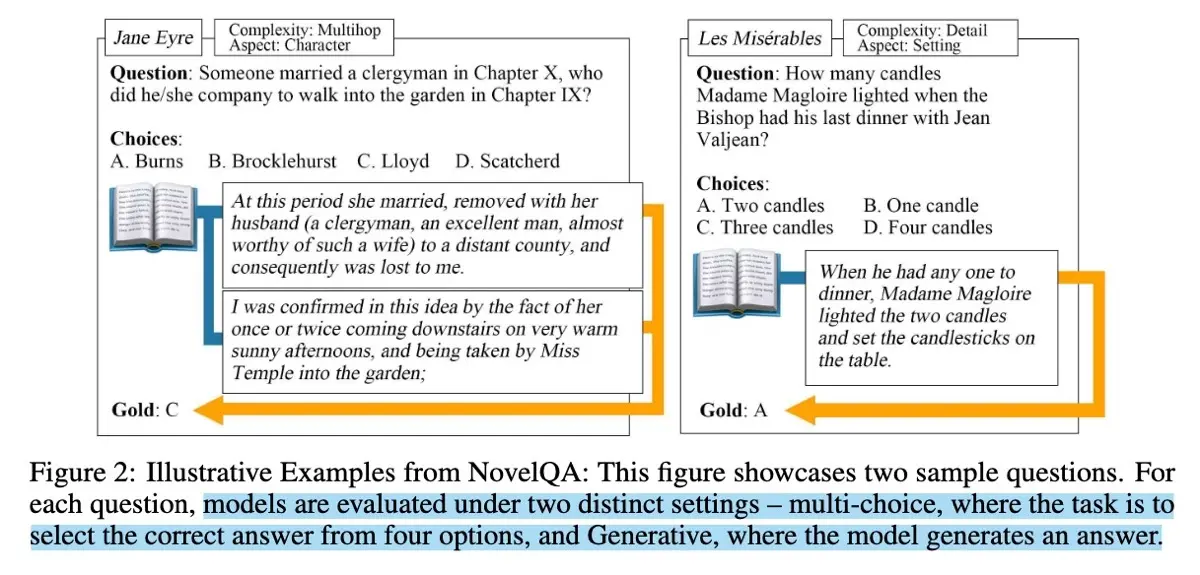
Statistics of the NarrativeQA dataset NarrativeQA evaluates whether models can integrate information dispersed throughout long narratives, such as entire books or movies, to produce coherent answers. Answers are evaluated on n-gram matching metrics such as BLEU, METEOR, and ROUGE, comparing machine-generated answers against two reference answers for each question. NarrativeQA highlights the importance of questions that go beyond simple extraction, requiring models to integrate information across the document. By generating questions from summaries instead of full texts, the authors ensured questions required holistic comprehension of the text, thus reducing superficial, extractive answering strategies. NovelQA, introduced by Wang et al. in 2024, is a benchmark designed for evaluating reading comprehension on very long texts, often exceeding 200,000 tokens. Similar to NarrativeQA but updated for modern times, NovelQA assesses how well models understand and integrate narratives spanning entire novels. Models were evaluated in two formats: multiple-choice and open-ended generation.
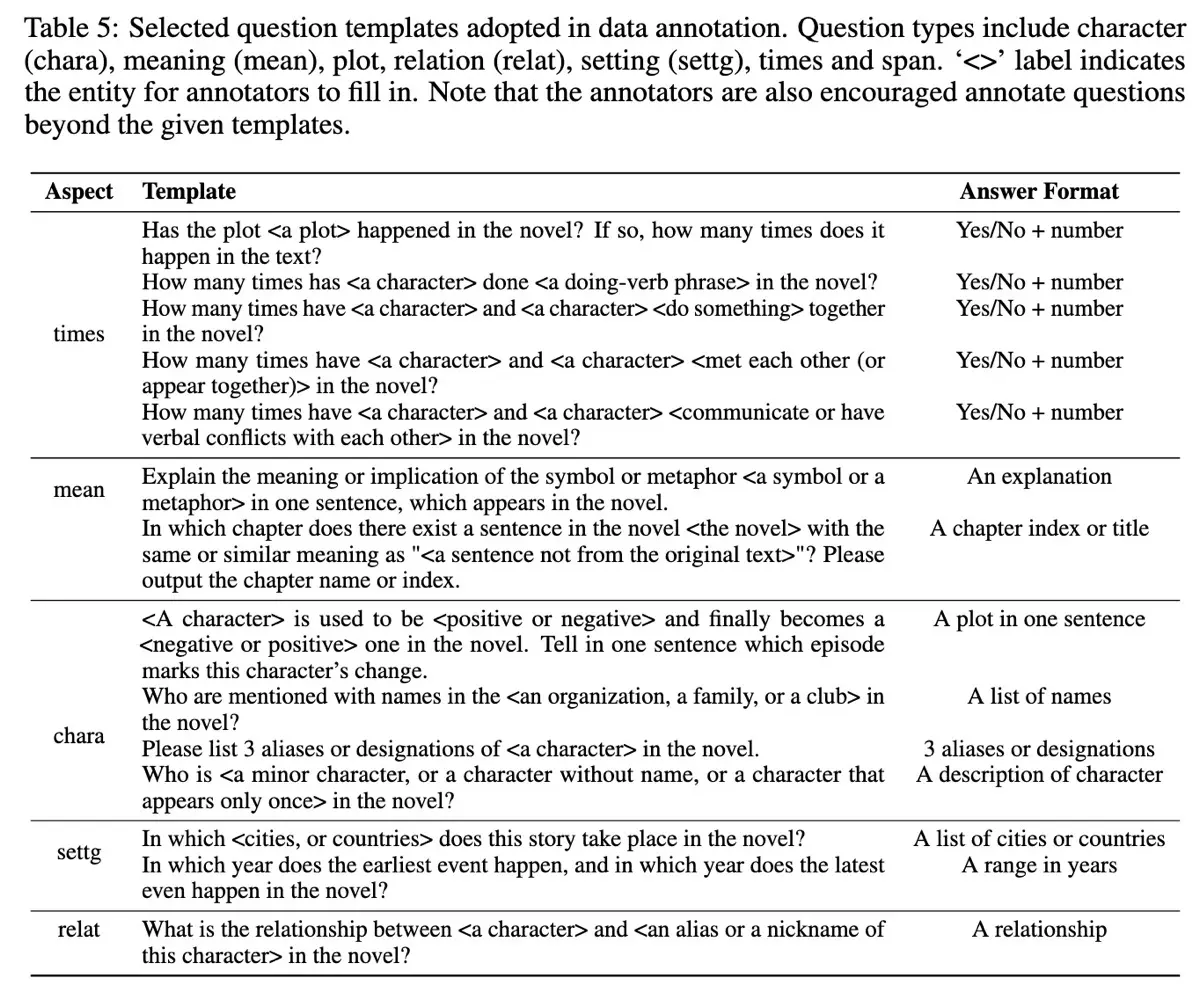
Two types of responses in NovelQA To build the dataset, the authors selected a diverse set of 89 English novels and collaborated closely with English literature students familiar with these works. Annotators created 2,305 questions in two phases. First, annotators used a question template and filled in entities from the novel to form valid questions (templates below).
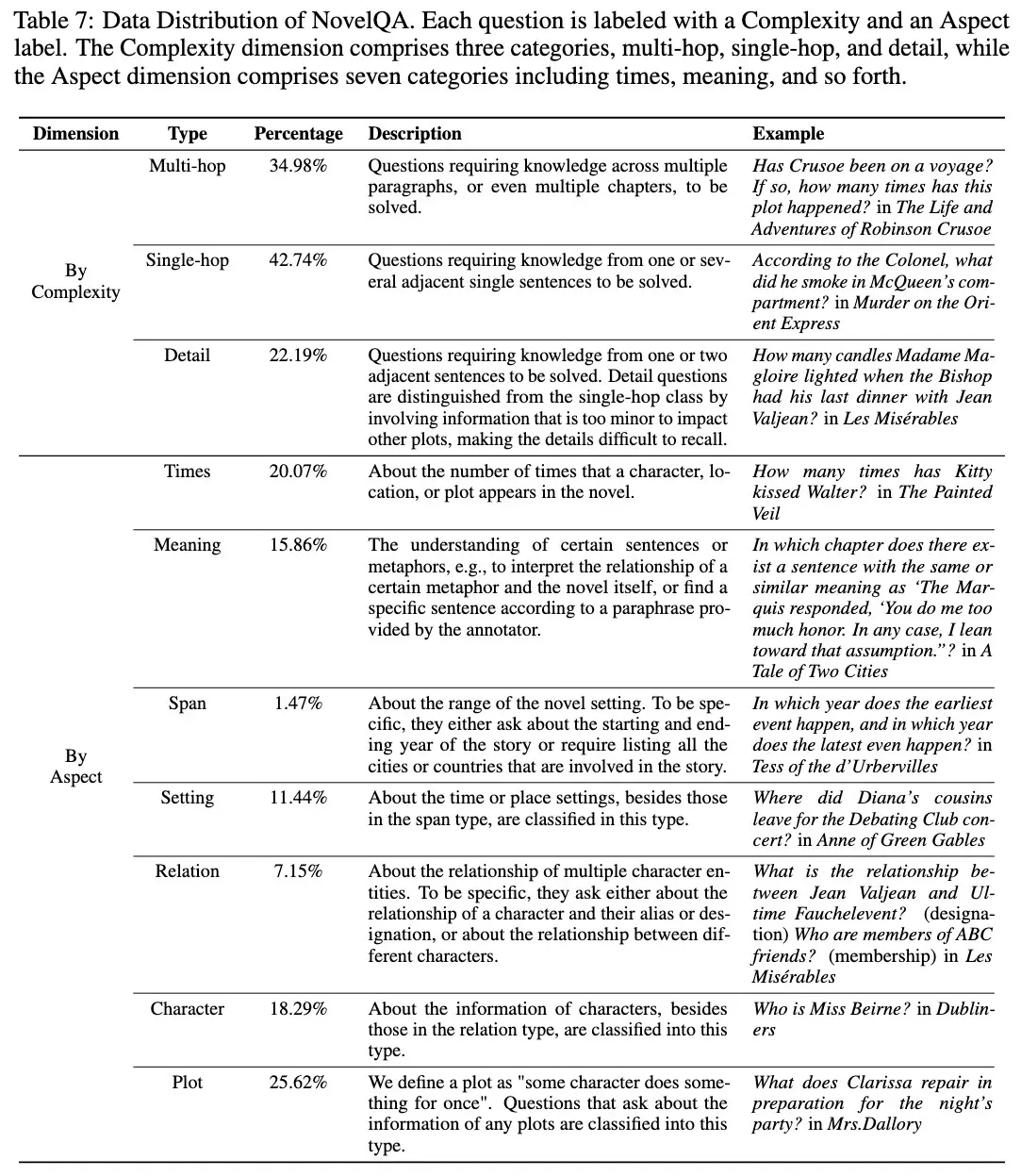
Templates used to generate questions in NovelQA Then, to enhance question diversity, annotators also freely generated challenging questions. All the questions were then reviewed by the authors, who ultimately accepted 79.4% of the questions. Each question was accompanied by a gold-standard answer and the relevant supporting evidence from the novels to ground evaluations. NovelQA evaluates a model’s ability to synthesize, integrate, and recall detailed information across extremely long contexts. Questions fall into these categories:
The questions cover various narrative aspects, such as characters, plot, setting, and deeper thematic meanings. The benchmark supports both multiple-choice and open-ended generative evaluation methods, with GPT-4 serving as evaluator for generative answers (achieving Cohen’s Kappa of 89.25% against human judgments).
Data distribution by complexity and aspect in NovelQA NovelQA’s findings are a shift from the typical “lost in the middle” problem—it showed that model performance declines when evidence appears beyond the 100,000-token mark. The authors also highlighted the importance of rigorous quality control, manually reviewing all crowd-generated questions and accepting only 79.4% of question-answer pairs. Finally, explicitly linking each answer to specific supporting evidence helps with retrieval evals.
Performance of models decline when evidence is beyond 100k tokens While narrative texts present one kind of challenge, comprehending dense, technical documents introduces an entirely different set of difficulties. QASPER, introduced by Dasigi et al. (2021), addresses this by testing models on information-seeking questions on academic papers. Specifically, QASPER contains 5,049 questions on 1,585 NLP papers. Similar to NarrativeQA, these questions were crafted by NLP practitioners who had only read paper titles and abstracts. This approach ensures questions often require synthesizing information across the entire paper rather than simple text extraction.
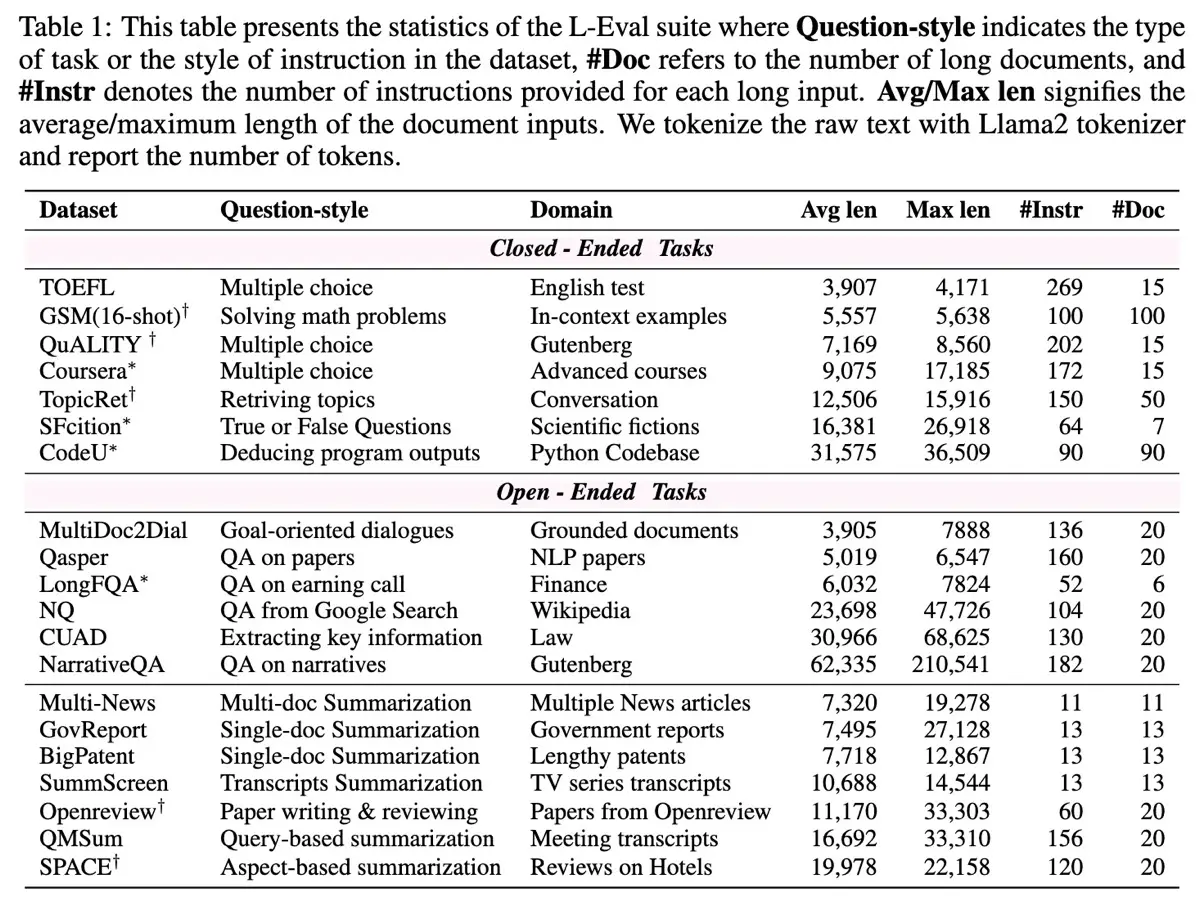
Example question, answer, and supporting evidence in QASPER First, 25 NLP practitioners selected papers that interested them and created questions based solely on titles and abstracts. Then, another group of 51 NLP experts answered these questions using the full texts. The latter group’s task included determining if questions were answerable, pinpointing specific supporting evidence (such as text passages, figures, or tables), and providing clear, concise answers. (10% of questions were marked unanswerable and thus excluded.) Separating question generation from answer annotation reduced biases, as question authors had no prior knowledge of the detailed answers. QASPER evaluates models on two main aspects: answer accuracy (Answer-F1) and evidence selection (Evidence-F1). Answer-F1 measures the accuracy of model responses, regardless of whether they extract text directly or create new explanations. Evidence-F1 evaluates the model’s ability to identify supporting details. This is particularly challenging, as more than half of the questions require combining evidence from multiple sections or paragraphs. The Evidence-F1 results in QASPER highlight a significant gap between answer generation and evidence retrieval—even when models give accurate answers, they often struggle to identify the exact supporting passages. Additionally, limiting question creators to only titles and abstracts naturally encouraged questions—and answers—that required a deep understanding of the entire paper, moving beyond superficial extraction. L-Eval by An et al. (2023) covers documents ranging from 3,000 to 200,000 tokens and includes 20 diverse subtasks, 508 extensive documents, and over 2,000 human-annotated question-answer pairs. Unlike previous benchmarks that mainly relied on text-matching metrics, L-Eval also applied LLM-evaluators and measured the difference between both. To build L-Eval, the authors first created four new datasets: Coursera (educational content), SFiction (science fiction stories), CodeU (Python codebases), and LongFQA (financial earnings). They also improved five existing datasets by adding more challenging synthesis-oriented questions, such as augmenting QuALITY to require deeper comprehension of entire documents. Lastly, they reviewed and corrected 12 tasks from prior benchmarks, using Claude-100k to identify and remove inaccuracies or unanswerable questions.
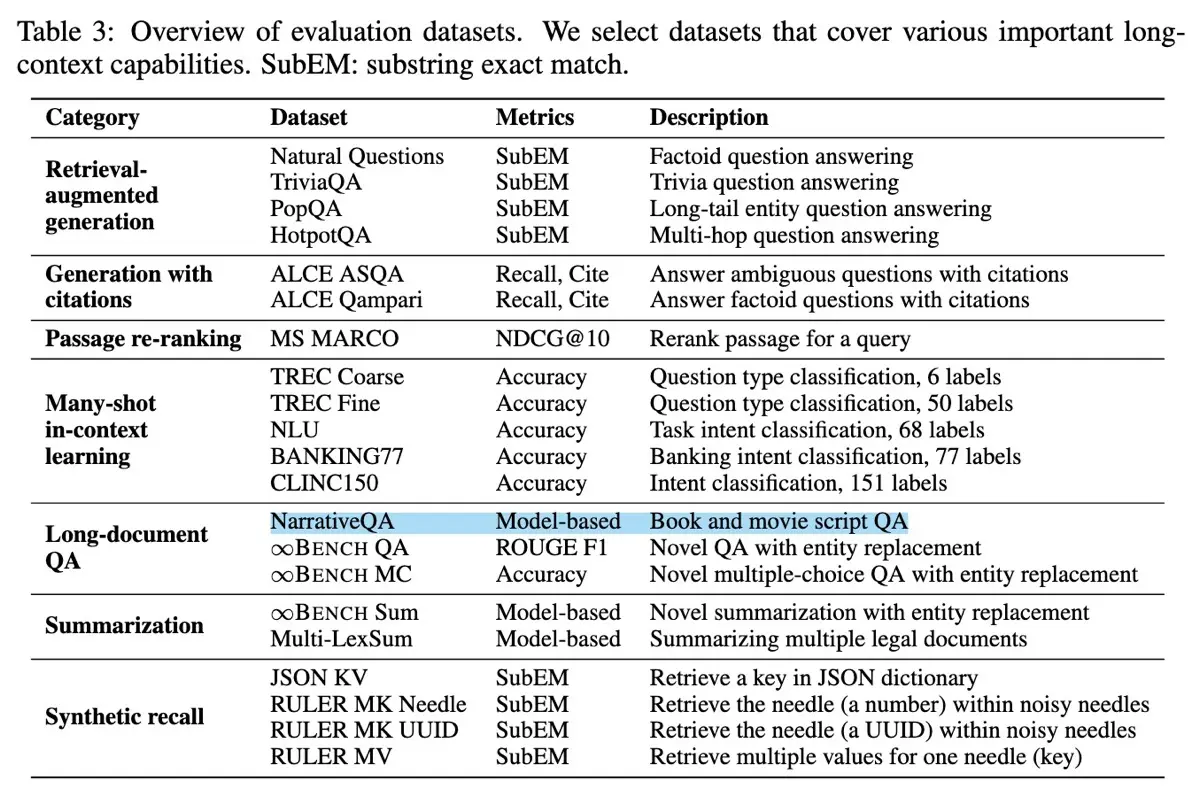
Statistics of datasets, question types, and domains in L-Eval L-Eval evaluates two types of tasks: closed-ended (like multiple-choice, code comprehension, true/false, and math), emphasizing precise reasoning, and open-ended (such as narrative synthesis and summarization), focusing on integrating and summarizing long-form content. Closed-ended tasks were evaluated via exact-match accuracy while open-ended tasks had human annotators rating responses from 1 (poor) to 5 (excellent). Additionally, L-Eval used language models like GPT-4 and GPT-3.5 as evaluators through pairwise comparisons for open-ended tasks. These had carefully designed prompts to reduce bias toward overly detailed answers. Traditional n-gram metrics, including ROUGE-L and F1 scores, were also used for efficiency, despite their known sensitivity to response length. L-Eval showed that traditional n-gram metrics often fail to reflect true comprehension in long-context scenarios due to mismatched answer lengths. Additionally, the benchmark demonstrated that using LLMs as evaluators in pairwise comparisons provides superior alignment with human assessments compared to traditional metrics, highlighting clear distinctions in model strengths for closed-ended versus open-ended tasks. HELMET (How to Evaluate Long-context Models Effectively and Thoroughly), introduced by Yen et al. (2025), addresses issues in earlier benchmarks, such as unrealistic tasks and inconsistent metrics, providing a framework for evaluating long-context language models. To start, the authors identified shortcomings in existing evaluations, including limited context lengths, unreliable methods, and inadequate coverage for non-instruction-tuned models. Then, they created a benchmark with seven task categories: Retrieval-Augmented Generation (RAG), generation with citations, passage re-ranking, many-shot in-context learning, long-document question-answering, summarization, and synthetic recall. Each task contains contexts of up to 128,000 tokens, allowing controlled and consistent assessments with carefully crafted few-shot prompts and model-based metrics.
Task categories, datasets, and metrics in HELMET HELMET specifically evaluates these capabilities in long-context models:
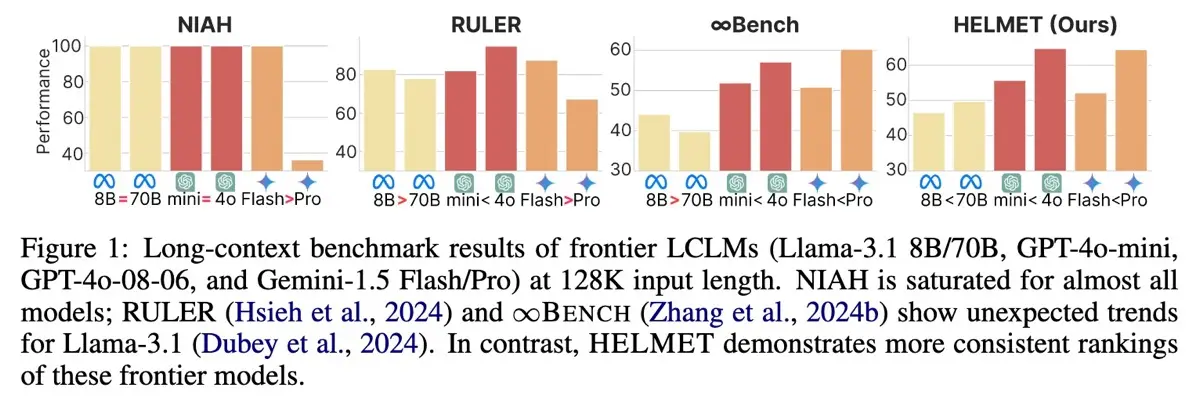
HELMET showed that synthetic tasks like Needle In a Haystack aren’t as useful, due to their weak correlation with real-world scenarios. Also, by carefully controlling input lengths, HELMET could evaluate model robustness to increasingly long contexts that approached previous models’ limits (≥128K tokens). Similar to previous benchmarks, HELMET replicated the flaws in traditional n-gram metrics such as ROUGE, which can misrepresent quality in longer outputs. Instead, it recommended using model-based evaluations, using models like GPT-4o, for evaluations that align more closely with human judgment.
Comparison of benchmark results across NIAH, Ruler, InfinityBench, and HELMET Loong, by Wang et al. (2024), is a benchmark that evaluates long-context comprehension across multiple documents. While most earlier benchmarks focus on single-document scenarios, Loong presents realistic, multi-document tasks where missing any relevant document results in incorrect answers.
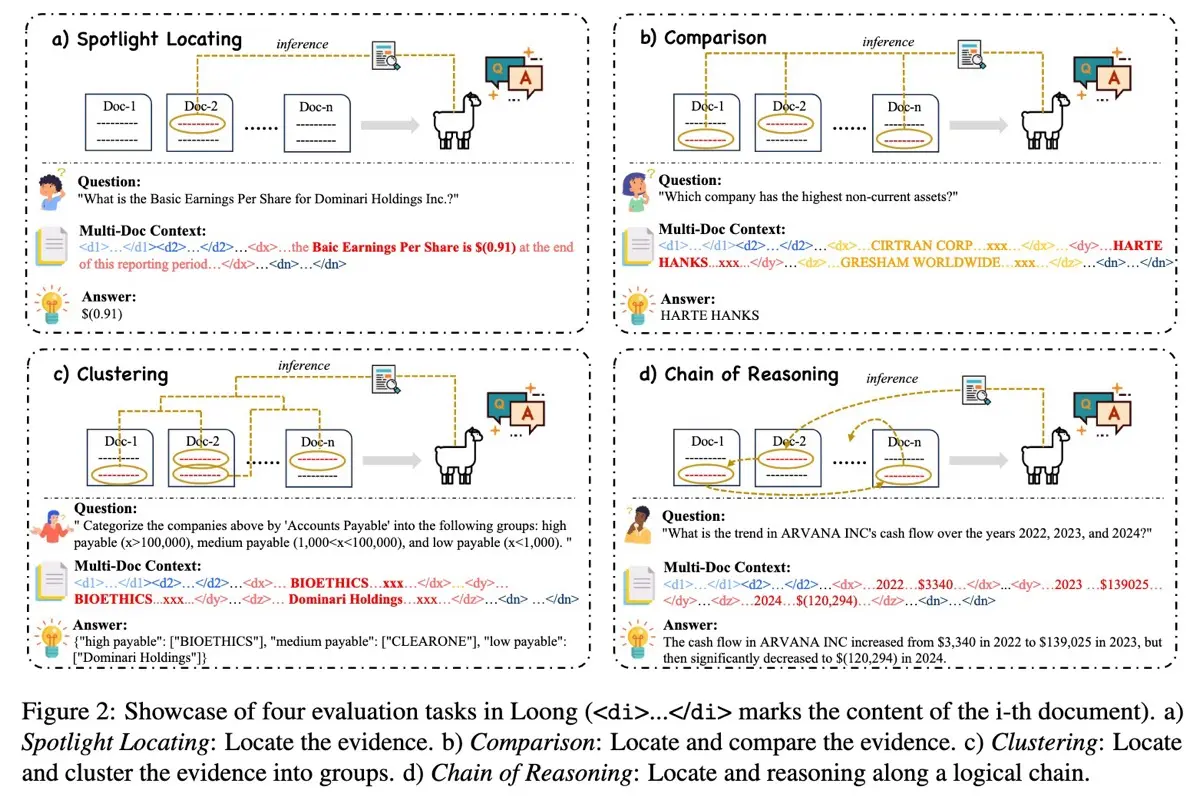
Loong focuses on multi-document Q&A Loong consists of 1,600 evals drawn from financial reports, legal cases, and academic papers in English and Chinese, mainly from 2024. Each task includes evidence spread across multiple documents, mimicking real-world complexity. To generate questions, the authors used two methods: template-based generation, where Q&A pairs were constructed through predefined rules, and free annotation, where GPT-4o was prompted to create additional Q&A pairs. Loong evaluates a model’s ability to locate, compare, cluster, and reason on evidence spread across multiple documents, typically ranging from 10,000 to over 250,000 tokens. The benchmark covers four task types:
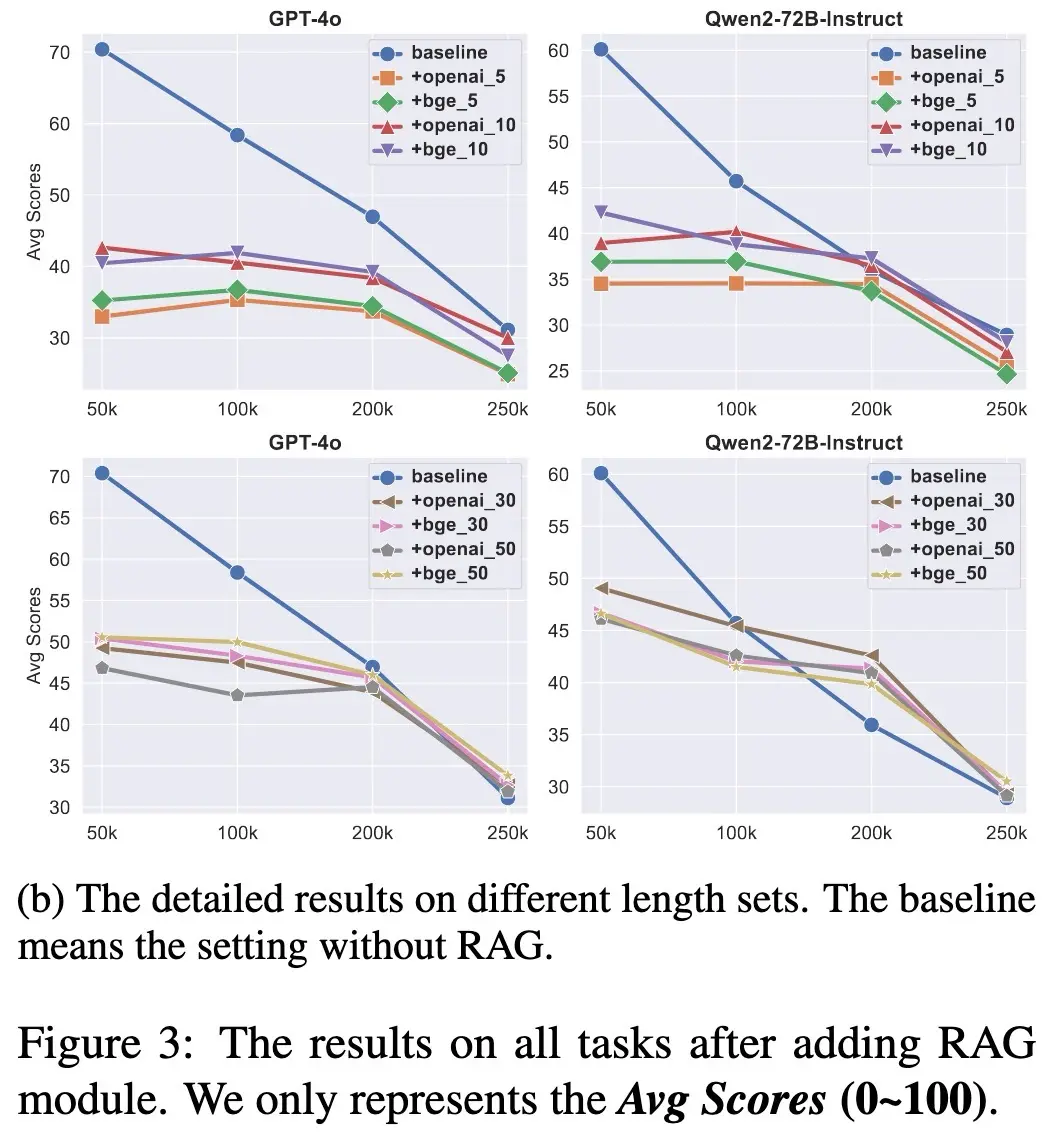
The four evaluation tasks in Loong For evaluation, GPT-4 was used as the LLM-evaluator to score model outputs based on accuracy, hallucinations, and completeness, referencing the golden answer and task requirements. Metrics included (i) average scores (the average evaluation across all questions) and (ii) perfect rate (the percentage of questions receiving a perfect score). Interestingly, their analysis of retrieval-augmented generation (RAG) showed that using RAG reduced performance on the Loong benchmark. They hypothesized that this is because Loong’s evidence is dispersed across multiple documents. While RAG helped somewhat on spotlight tasks, it performed poorly on tasks demanding deeper synthesis, such as comparison, clustering, and multi-step reasoning.
The use of RAG degrades performance compared to the baseline Here are some other long-context benchmarks that you may find helpful:
• • • Whew, that was a lot! Here are some key takeaways:
Did I miss anything important? Any other metrics, methods, or benchmarks you’d suggest I look into? Please let me know! |



Eugene Yan
I build ML, RecSys, and LLM systems that serve customers at scale, and write about what I learn along the way. Join 7,500+ subscribers!
Hey friends, How can we work effectively with AI? What’s the workflow and how does it scale? And ideally, it should compound. Every finished artifact—code, docs, analysis, decisions—becomes context for the next session. And each correction updates a config that reduces future errors. While I’m still learning, I’ve repeated my answers often enough that I’m writing it here so the next time I’m asked I can share a link instead. I appreciate you receiving this, but if you want to stop, simply...
Hey friends, After repeating myself for the nth time on how to build product evals, I figured I should write it down. There are three basic steps: (i) labeling a small dataset, (ii) aligning our LLM evaluators, and (iii) running the experiment + evaluation harness with each config change. I appreciate you receiving this, but if you want to stop, simply unsubscribe. • • • 👉 Read in browser for best experience (web version has extras & images) 👈 First, label some data It begins with sampling...
Hey friends, What makes an effective principal engineer or scientist? I’ve distilled what I’ve observed from role models and quoted some of their advice below. While my perspective is Amazon-centric, these ideas should also apply to most principal tech IC roles. As always, use your best judgment and assess if this advice applies to you and your situation. I appreciate you receiving this, but if you want to stop, simply unsubscribe. 👉 Read in browser for best experience (web version has extras...