I build ML, RecSys, and LLM systems that serve customers at scale, and write about what I learn along the way. Join 7,500+ subscribers!
Stop Blaming the LLM-as-Judge—Fix Your Process Instead
|
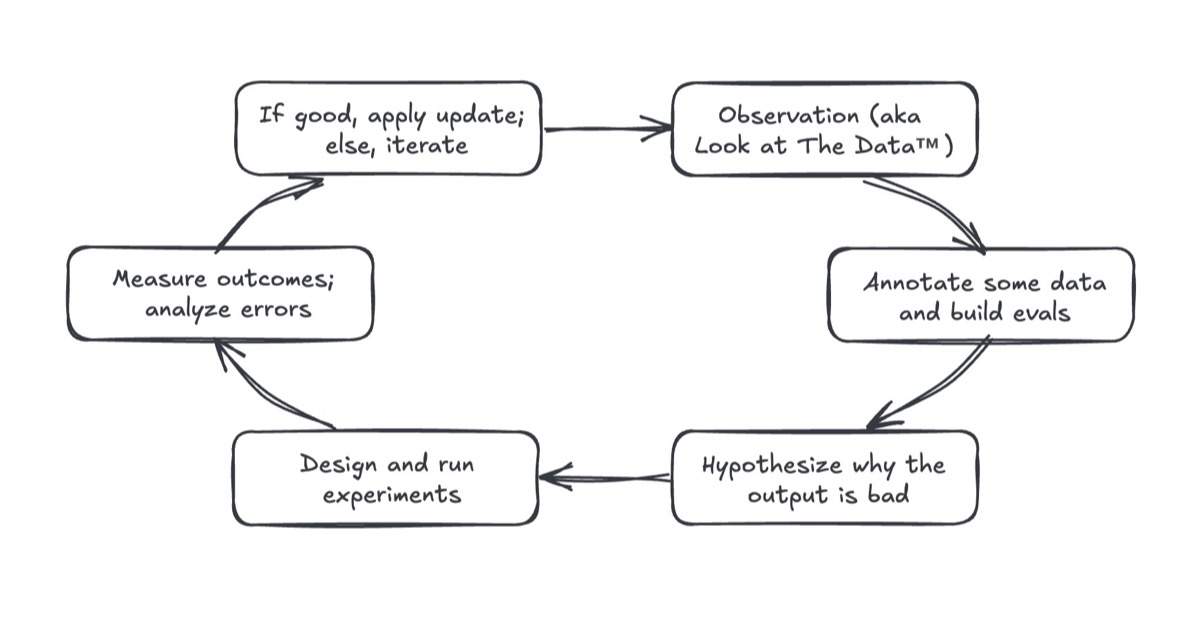
Hey friends, I've seen many teams misunderstand what it means to build and apply product evals and wrote this piece to address it. I hope it clarifies that evals aren't a one and done artifact, but a disciplined process. Do you agree or disagree? Please reply and let me know! P.S., In May, my friends Hamel Husain and Shreya Shankar are teaching an exclusive 4-week course on "AI Evals for Engineers & PMs". They've generously provided a special 40% discount link 🤫—but hurry, limited spots available! I appreciate you receiving this, but if you want to stop, simply unsubscribe. • • • 👉 Read in browser for best experience (web version has extras & images) 👈 Product evals are misunderstood. Some folks think that adding another tool, metric, or LLM-as-judge will solve the problems and save the product. But this sidesteps the core problem and avoids the real work. Evals aren’t static artifacts or quick fixes; they’re practices that apply the scientific method, eval-driven development, and AI output monitoring. Building product evals is simply the scientific method in disguise. That’s the secret sauce. It’s a cycle of inquiry, experimentation, and analysis. It starts with observation aka Look at The Data™. This means examining our inputs, AI outputs, and how users interact with our systems. By looking at the data, we learn where the system works well, and perhaps more crucially, where it fails. Identifying these failure modes is the starting point for meaningful improvement. Then, we annotate some data, prioritizing problematic outputs. This means labeling samples of successes and failures to build a balanced and representative dataset. Ideally, we should have a 50:50 split of passes and fails that spans the distribution of inputs. This dataset forms the foundation for targeted evals that track performance on the issues we’ve identified. Next, we hypothesize why specific failures occur. Perhaps our RAG’s retrieval isn’t returning the relevant context, or maybe the model struggles to follow the complex—and sometimes conflicting—instructions. By looking at data such as retrieved documents, reasoning traces, and erroneous outputs, we can prioritize failures to fix and hypotheses to test. Then, we design and run experiments to test our hypotheses. Experiments could involve rewriting prompts, updating retrieval components, or switching to a different model. A good experiment defines the outcomes that confirm or invalidate the hypotheses. Ideally, it should also include a baseline or control condition against which to compare. Measuring outcomes and analyzing errors is often the most challenging step. Unlike casual vibe checks, this requires quantifying whether an experiment’s updates actually improved outcomes: Did accuracy increase? Were fewer defects generated? Does the new version do better in pairwise comparisons? We can’t improve outcomes if we can’t measure it. If an experiment succeeds, we apply the update; if it fails, we dig into the error analysis, refine our hypotheses, and try again. Through this iterative loop, product evals becomes the data flywheel that improves our product, reduces defects, and earns user trust.
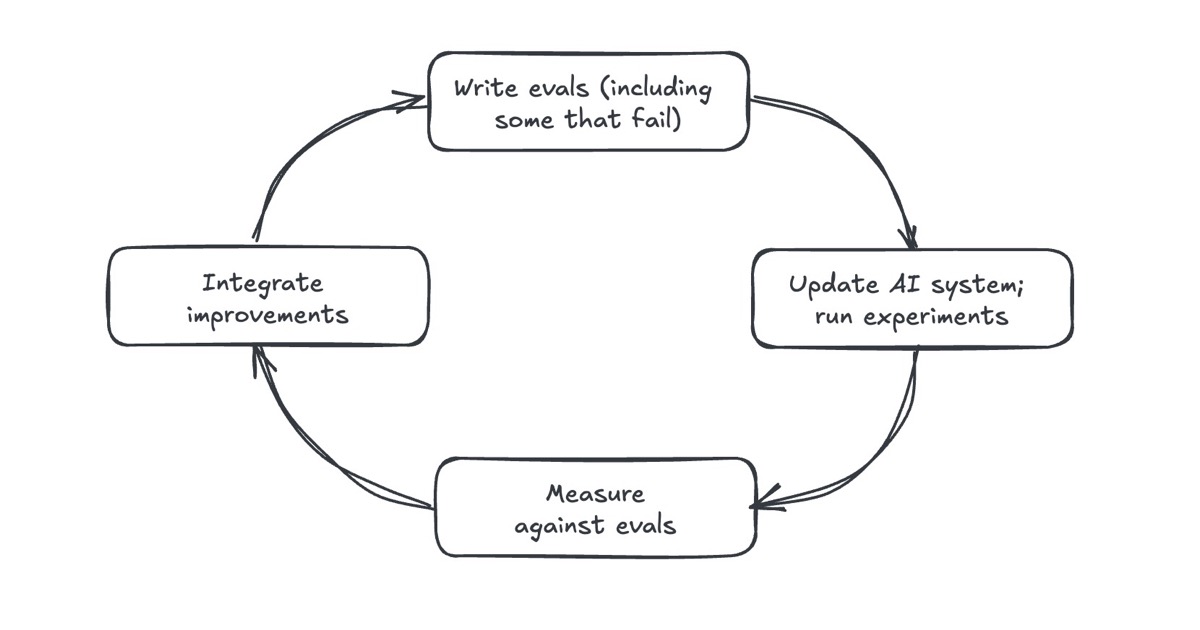
Eval-driven development (EDD) helps us build better AI products. It’s similar to test-driven development where we write tests before implementing software that passes those tests. EDD follows the same philosophy: Before developing an AI feature, we define success criteria, via product evals, to ensure alignment and measurability from day one. Here’s a secret: Machine learning teams have practiced this for decades, where we build models and systems against validation and test sets. They’re all the same concept but with different names. In EDD, evals guide our development. We start by evaluating a baseline, perhaps a simple prompt, to get an initial benchmark. From then on, every prompt tweak, every system update, every iteration, is evaluated. Did simplifying the prompt improve faithfulness? Did updating retrieval increase the recall of relevant documents? Or did the update worsen performance? Because EDD provides immediate, objective feedback, we can see what’s improving and what’s not. This cycle—write evals, make changes, run evals, integrate improvements—ensures measurable progress. Instead of relying on vague, intuition-based perceptions, we build a feedback loop grounded in software engineering practices.
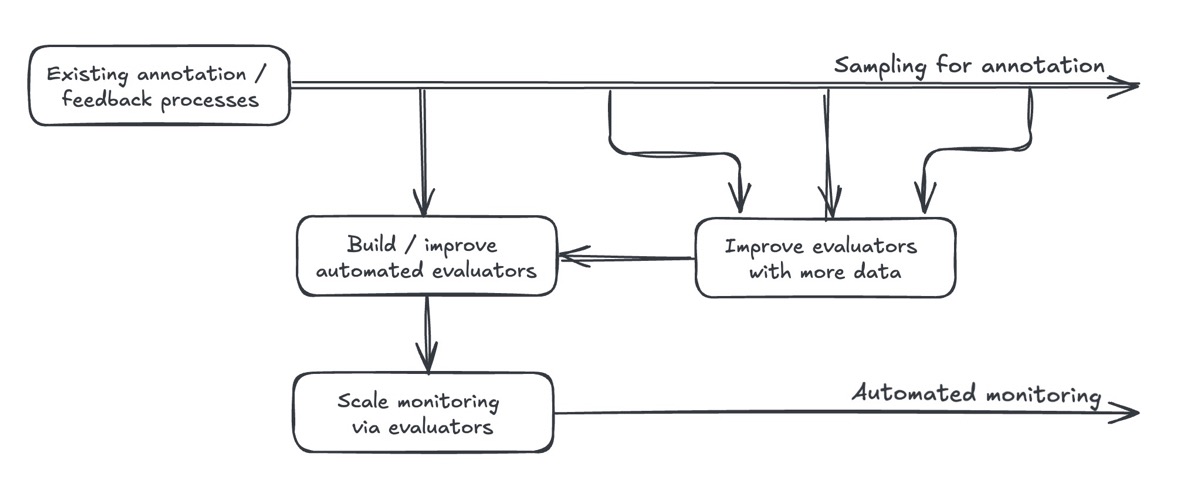
Automated evaluators (aka LLM-as-judge) don’t eliminate the need for human oversight. While they help scale monitoring, they can’t compensate for neglect. If we’re not actively reviewing AI outputs and customer feedback, automated evaluators won’t save our product. To evaluate and monitor AI products, we typically sample outputs and annotate them for quality and defects. With enough high-quality annotations, we can calibrate automated evaluators to align with human judgment. This could mean measuring recall or precision on binary labels, or correlation when deciding between outputs via pairwise comparisons. Once properly aligned, these evaluators help scale the continuous monitoring of AI systems. But having automated evaluators doesn’t remove the need for human oversight. We still need to periodically sample and annotate data, and analyze user feedback. Ideally, we should design products that capture implicit feedback through user interactions. Nonetheless, explicit feedback, while less frequent and occasionally biased, can also be valuable. (Read more.) Also, while automated evaluators scale well, they aren’t perfect. But neither are human annotators. Nonetheless, by collecting more and higher-quality annotations, we can better align these evaluators. Organizational discipline is crucial to maintain this feedback loop of sampling data, annotating outputs, and improving automated evaluators.
• • • While building with AI can feel like magic, building AI products still takes elbow grease. If teams don’t apply the scientific method, practice eval-driven development, and monitor the system’s output, buying or building yet another evaluation tool won’t save the product. |
Eugene Yan
I build ML, RecSys, and LLM systems that serve customers at scale, and write about what I learn along the way. Join 7,500+ subscribers!
Hey friends, How can we work effectively with AI? What’s the workflow and how does it scale? And ideally, it should compound. Every finished artifact—code, docs, analysis, decisions—becomes context for the next session. And each correction updates a config that reduces future errors. While I’m still learning, I’ve repeated my answers often enough that I’m writing it here so the next time I’m asked I can share a link instead. I appreciate you receiving this, but if you want to stop, simply...
Hey friends, After repeating myself for the nth time on how to build product evals, I figured I should write it down. There are three basic steps: (i) labeling a small dataset, (ii) aligning our LLM evaluators, and (iii) running the experiment + evaluation harness with each config change. I appreciate you receiving this, but if you want to stop, simply unsubscribe. • • • 👉 Read in browser for best experience (web version has extras & images) 👈 First, label some data It begins with sampling...
Hey friends, What makes an effective principal engineer or scientist? I’ve distilled what I’ve observed from role models and quoted some of their advice below. While my perspective is Amazon-centric, these ideas should also apply to most principal tech IC roles. As always, use your best judgment and assess if this advice applies to you and your situation. I appreciate you receiving this, but if you want to stop, simply unsubscribe. 👉 Read in browser for best experience (web version has extras...